
How Much do Scoring Methods Matter for Causal Inference?
The manner in which student outcomes are measured, scored, and analyzed often receives too little attention in randomized experiments. In this study, we aimed to explore the consequences of different scoring approaches for causal inference on test score data. We compared the performance of four methods, Classical Test Theory (CTT) sum scores, CTT mean scores, item response theory (IRT) scores, and the Explanatory Item Response Model (EIRM). In contrast to the CTT- and IRT-based approaches that score the test and estimate treatment effects in two separate steps, the EIRM is a latent variable model that allows for simultaneous estimation of student ability and the treatment effect. The EIRM has a long history in psychometric research, but applications to empirical causal inference settings are rare. Our results show that which model performs best depends on the context.
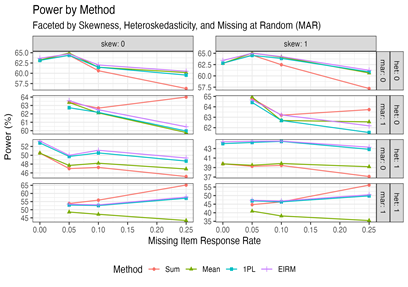
How to Read this Chart: Statistical power (y-axis) by missing item response rate (x-axis) and estimation method (color and shape) shows that the relative performance of each approach depends on the context. The EIRM and IRT-based scores are more robust to missing data and provide the most benefits to power when the latent trait is heteroskedastic. Legend: skew = latent trait is skewed, het = latent trait is heteroskedastic, mar = item responses are missing at random, sum = sum score, mean = mean score, 1PL = IRT theta score, EIRM = explanatory item response model.
Comparative Model Performance